Modul Zonen OCR, Barcode, QRCode
Mit Zonen OCR können Sie Bereiche (Zonen) von Seiten eines Dokumentes erfassen. Eine Zone kann Text, Tabelle oder einen Barcode (Strich oder Matrix) enthalten. Der erfasste Inhalt wird in Variablen geschrieben, die z.B. für die Erzeugung einer Metadatei genutzt werden können.
Wird durch dieses Modul eine Trennung des eingescannten Papierstapels (oder der zugeführten Datei im Dokumentenworkflow) durchgeführt, wird für jeden Abschnitt ein neuer Workflow erzeugt und der Ursprungsworkflow beendet (dies ist z.B. auch unter Gelaufene Workflows erkennbar). Soll in einem Workflow eine Trennung erfolgen und Daten z.B. aus Barcodes gelesen werden, ist es empfehlenswert, die Trennung (z.B. anhand nur eines Barcodes) im ersten Modul durchzuführen. Wenn von der Seite noch weitere Daten gelesen werden sollen, kann die Seite behalten werden - in einem zweiten OCR-Modul braucht dann nur die erste Seite durchsucht zu werden (auf der ja der Trenn-Barcode gefunden wurde) und weitere Barcodes können auf dieser Seite gesucht und gelesen werden (so müssen nicht alle Seiten nach allen Zonen durchsucht werden). Wenn gewünscht, kann die Seite im zweiten OCR-Modul entfernt werden.
Es können in allen Eingabefeldern Variablen verwendet werden, siehe Variablen.
Die eingesetzte Grafik-Engine kann Bilder mit max. 8.400 Pixel Bildlänge verarbeiten (z.B. DIN-A3 mit 600dpi hat 16,5 Inch x 600 dpi= 9.900 Pixel).
Das Modul kann mehrfach im Workflow vorkommen.
Keine einschränkenden Module.
Im Zonen-Editor können Sie die Zonen auf beispielhaften Seiten markieren und alle erforderlichen Einstellungen für die Zonen vornehmen. Gehen Sie wie folgt vor.
Scannen Sie dazu zunächst die beispielhaften Seiten einzeln ein, die die Bereiche enthalten, die markiert werden sollen. Das Dateiformat jeder Seite muss dabei .jpg (JPEG) sein. Wählen Sie die Scaneinstellungen für die Vorlage (z.B. Farbe und Auflösung) so wie die Dokumente später gescannt werden sollen. Liegt die Datei bereits vor, wandeln sie das Dateiformat in JPEG.
Klicken Sie dann auf die Schaltfläche Dateien hierher ziehen oder klicken zum Hochladen und wählen Sie das Dokument im Dateibrowser aus (alternativ können Sie die gewünschte Datei auch per Drag and Drop auf diese Schaltfläche ziehen). Haben Sie mehrere Seiten, wiederholen Sie diesen Schritt für die weiteren Seiten. Die Seiten werden im rechtsseitigen Einstellungsbereich klein dargestellt.
Bilddateien für Zonen-OCR werden auch im Verzeichnis WorkflowFiles gespeichert. Nach einer Änderung des Pfades müssen diese in den neuen Pfad kopiert oder über die Webadministration neu hochgeladen werden. Das Bild dient aber nur der Visualisierung beim Konfigurieren des Zonen-OCRs - für die eigentliche Ausführung eines Zonen-OCR Vorgangs ist es nicht erforderlich.
Sobald eine Seite hinzugefügt wurde, werden die Einstelldialoge für die Zonendefinition sichtbar. Es können definiert werden:
- Zonen für erste Seite
- Zonen für alle Seiten
- Zonen für gerade Seiten
- Zonen für ungerade Seiten
- Zonen für letzte Seite
Es kann also festgelegt werden, auf welchen Seiten eines mehrseitigen Dokumentes die Zonen gesucht und ausgewertet werden sollen. Die Anzahl der im jeweiligen Bereich definierten Zonen wird nach der Zonenbezeichnung angezeigt.
Im Einstellungsbereich wählen Sie zunächst ein Seiten-Bild aus der Klappliste aus. Das Seitenbild wird nach kurzer Zeit auf der linken Seite groß dargestellt.
Klicken Sie nun auf Zone hinzufügen. Ein rechteckiger Marker wird in der Seite eingeblendet. Ziehen Sie ihn mit gedrückter Maustaste über den Bereich, der gescannt werden soll. Ändern Sie die Größe durch Ziehen an den kleinen Quadraten an Seiten und Ecken. Bemessen Sie die Zone nicht zu knapp, da nicht jedes Dokument ganz genau gleich gescannt wird.
Jede Zone können Sie in den Zonen-Einstellungen benennen. Der Einstellungsbereich erscheint automatisch beim Hinzufügen der Zone. In den Einstellungen können Sie eine Zone wieder löschen.
Zonen dürfen nicht gleich heißen. Zonen vom Typ Text dürfen sich nicht überschneiden.
Für jede Zone gibt es einen separaten Einstellungsbereich, der mit dem Namen der Zone gekennzeichnet ist.
Mit der Schaltfläche Zone löschen haben Sie die Möglichkeit eine Zone zu entfernen. Alle Einstellungen der Zone sowie die Zonenmarkierung auf dem Seitenbild werden entfernt.
Mit der Testfunktion wird die Zone in das erscheinende Textfenster getestet. Dort erscheint der Text, der erkannt oder aus einem Barcode gelesen wurde. Dabei werden alle relevanten Einstellungen für den gelesenen Text berücksichtigt (Anzahl der Worte oder Leerzeichen trimmen).
Der Name der Zone wird oberhalb der Zonenmarkierung angezeigt. Der Name ist wichtig für das Ansprechen der Zoneninhalte mit Variablen (Variablen beinhalten den Zonennamen). Bei der Änderung des Namens ist aus diesem Grunde Vorsicht geboten, da die Variablen (siehe Variablen) möglicherweise bei Scanzielen in der Metadatei-Generierung verwendet wurden (siehe auch Modul Scanziel SMB). Der Name der Zone wird oberhalb der Zonenmarkierung angezeigt.
Variablennamen dürfen keine Sonderzeichen enthalten. Erlaubt sind kleine und große Buchstaben (keine Umlaute o.Ä.), Zahlen und der Punkt ".".
Wird der Variablenname an mehreren Stellen verwendet, können alle Stellen den Variablenwert beeinflussen.
Beachten Sie beim Ändern des Namens der Zone, dass ggf. in Metadateien verwendete Variablen nicht mehr aufgelöst werden können.
Geben Sie bei Typ an, was in der Zone enthalten ist. Die folgenden Möglichkeiten stehen zur Verfügung.
Der erwartete Inhalt ist reiner Text. Der gesamte Text, der erkannt wurde, wird in die Variable %OCRZONE.<Zonenname>% geschrieben, z.B. %OCRZONE.Zone 1%. Der Text kann auch Zeilenumbrüche enthalten.
Der Inhalt der Zone wird als Tabelle interpretiert. Es wird je erkannter Tabellenspalte eine Variable erzeugt (%OCRTABLE.<Zonenname>.COL<Spaltennr.>% also für Spalte 1: %OCRTABLE.Zone 1.COL1% oder für Spalte 5: %OCRTABLE.Zone 1.COL5%). Bei der Ausgabe in einer Metadatei wird die Zeile so oft wiederholt, wie Zeilen in der Tabelle erkannt wurden.
Es kann auch die ganze Tabelle als .csv-Struktur ausgegeben werden. Dazu verwenden Sie die Variable %OCRZONE.<Zonenname>% (z.B. %OCRZONE.Zone 1%). Die Werte werden in doppelte Hochkomma eingefasst und mit Semikolon getrennt. Beispiel:
"Datum:";"11.10.2017";
"Benutzername:";"user54";
"Ordner:";"Allgemein";
Der Barcode 1D ist ein Code, der im Wesentlichen aus Strichen besteht. Es werden die nachstehenden Typen unterstützt.
 Der EAN-13 (Europäischen Artikelnummer) Code wird zur Kennzeichnung von Produkten verwendet um sie an der Kasse schnell erfassen zu können. Der Code ist üblicherweise mit dem Codeinhalt im Klartext versehen.
Der EAN-13 (Europäischen Artikelnummer) Code wird zur Kennzeichnung von Produkten verwendet um sie an der Kasse schnell erfassen zu können. Der Code ist üblicherweise mit dem Codeinhalt im Klartext versehen.
Siehe auch https://de.wikipedia.org/wiki/European_Article_Number.
 Der EAN-8 ist eine verkürzte Version des EAN-13. Dieser Code findet normalerweise nur bei Artikeln Verwendung, die nicht genug Platz für den EAN-13 Code haben (wird nur auf Antrag vergeben). Der Code ist (wie der EAN-13) üblicherweise mit dem Codeinhalt im Klartext versehen.
Der EAN-8 ist eine verkürzte Version des EAN-13. Dieser Code findet normalerweise nur bei Artikeln Verwendung, die nicht genug Platz für den EAN-13 Code haben (wird nur auf Antrag vergeben). Der Code ist (wie der EAN-13) üblicherweise mit dem Codeinhalt im Klartext versehen.
Siehe auch https://de.wikipedia.org/wiki/European_Article_Number.
 Mit dem Code 128 Auto kann der volle ASCII-Zeichensatz dargestellt werden. Die drei möglichen Zeichensätze werden unterstützt (A, B und C).
Mit dem Code 128 Auto kann der volle ASCII-Zeichensatz dargestellt werden. Die drei möglichen Zeichensätze werden unterstützt (A, B und C).
Code 128A: Großbuchstaben und Sonderzeichen
Code 128B: Groß- und die Kleinbuchstaben
Code 128C: Ziffern
Siehe auch https://de.wikipedia.org/wiki/Code128.
 Der Code-39 ist ein alphanumerischer Code mit eher geringer Informationsdichte, aber mit großem Zeichenvorrat.
Der Code-39 ist ein alphanumerischer Code mit eher geringer Informationsdichte, aber mit großem Zeichenvorrat.
Siehe auch https://de.wikipedia.org/wiki/Code39.
 Der ITF-Code ist ein Derivat des Code 25 interleaved (2 of 5 interleaved) und wird häufig zur Kennzeichnung von Paletten oder Kartons verwendet, deren Produkte mit einem EAN-13 Code gekennzeichnet sind.
Der ITF-Code ist ein Derivat des Code 25 interleaved (2 of 5 interleaved) und wird häufig zur Kennzeichnung von Paletten oder Kartons verwendet, deren Produkte mit einem EAN-13 Code gekennzeichnet sind.
 Der QR Code ist ein quadratischer 2D Code. Die Markierungen in drei Ecken der Matrix geben die Ausrichtung vor. Der Code ist besonders durch das Einlesen durch Handys beliebt.
Der QR Code ist ein quadratischer 2D Code. Die Markierungen in drei Ecken der Matrix geben die Ausrichtung vor. Der Code ist besonders durch das Einlesen durch Handys beliebt.
Siehe auch https://de.wikipedia.org/wiki/QR-Code.
 Der PDF417 ist ein 2D Code, welcher aus gestapelten Strichcodes besteht (Stapelcode). Die verwendeten Zeichen werden in Wörtern codiert. Ein Codewort besteht aus 17 Modulen, die jeweils aus 4 Strichen und 4 Lücken bestehen.
Der PDF417 ist ein 2D Code, welcher aus gestapelten Strichcodes besteht (Stapelcode). Die verwendeten Zeichen werden in Wörtern codiert. Ein Codewort besteht aus 17 Modulen, die jeweils aus 4 Strichen und 4 Lücken bestehen.
Siehe auch https://de.wikipedia.org/wiki/PDF417.
 Der Data Matrix Code ist einer der bekanntesten 2D-Codes. Die Größe des üblicherweise quadratischen Codes wird dabei aus einer großen Auswahlmenge bestimmt.
Der Data Matrix Code ist einer der bekanntesten 2D-Codes. Die Größe des üblicherweise quadratischen Codes wird dabei aus einer großen Auswahlmenge bestimmt.
Siehe auch https://de.wikipedia.org/wiki/DataMatrix-Code.

Der Aztec Code ist ein 2D-Code, der sich durch ein Suchelement in der Mitte des Codes auszeichnet.
Siehe auch https://de.wikipedia.org/wiki/Aztec-Code.
Die Sprachen der OCR-Erkennung können für die zu verarbeitenden Dokumente festgelegt werden (sie ist nicht am Gerät einstellbar). Damit wird die Erkennungsrate für z.B. in kyrillischen Zeichen verfassten Dokumenten verbessert.
Je mehr Sprachen gleichzeitig ausgewählt werden, desto schwieriger wird es für die OCR-Erkennung die richtigen Zeichen auszuwählen, da es z.B. lateinische Schriftzeichen oder Worte gibt, die kyrilischen sehr ähnlich sind. Sie erhalten das beste Ergebnis, wenn die Voreinstellung möglichst nur die (eine) Sprache der gescannten Dokumente enthält. Wird gar keine Sprache ausgewählt wird der Standard (Englisch und Deutsch) verwendet.
-
Englisch
-
Deutsch
-
Russisch
-
Ukrainisch
Anhand des Inhaltes der gelesenen Zone kann veranlasst werden, dass der Scan an dieser Stelle getrennt wird. Entscheidend dafür ist die Bedingung für die Seitentrennung (diese Einstellung wird nur angezeigt, wenn die Seitentrennung aktiv ist).
Technisch betrachtet wird - sobald eine Trennung durchgeführt wird - für jedes getrennte Dokument eine neue Instanz des Workflows gestartet. Diese Instanzen laufen dann über das trennende Zonen-OCR-Modul hinweg und führen den Workflow weiter aus (ggf. kann hier auch ein weiteres Zonen-OCR-Modul folgen).
Nicht trennen: Die Seitentrennung ist nicht aktiviert.
Trennen und behalten: Der Scan wird an der Seiten, an dem die Bedingung für den Zoneninhalt zutrifft getrennt. Die Seite mit der trennenden Zone wird als erste Seite des neuen Dokumentes verwendet.
Trennen und entfernen: Der Scan wird an der Seiten, an dem die Bedingung für den Zoneninhalt zutrifft getrennt. Die Seite mit der trennenden Zone wird aus dem Scan entfernt.
Nach Inhalt gruppieren: Die getrennten Abschnitte mit gleichem Zoneninhalt werden in einer Datei zusammengeführt (in der Reihenfolge, in der sie gescannt wurden). Es entstehen also so viele Dateien, wie es unterschiedliche Zoneninhalte im gescannten Stapel gibt.
Wenn eine Seite mehrere Zonen besitzt, tragen Sie die Angaben für die Seitentrennung nur bei einer Zone ein. Einträge in mehreren Zonen können zu einem unerwarteten Ergebnis führen.
Geben Sie hier die Bedingung ein, die dafür sorgt, dass die Seitentrennung durchgeführt wird. Es können Wildcards oder reguläre Ausdrücke verwenden (nicht beides gleichzeitig).
Die Bedingung für die Seitentrennung wird auf den gefilterten Zoneninhalt angewendet.
Als Wildcards können Sternchen (*) für beliebig viele unbekannte Zeichen und Fragezeichen (?) für ein unbekanntes Zeichen verwendet werden.
Beispiele:
Rechnung: Das Dokument wird getrennt wenn die Zone (genau) das Wort Rechnung enthält.
*Rechnung*: Die Trennung erfolgt, wenn im Zonentext irgendwo das Wort Rechnung vorkommt (die Zone kann mehr Text enthalten).
*a?tiv*: Getrennt wird, wenn irgendwo im Text aktiv oder active (oder ähnliches, was dem Suchfilter entspricht) vorkommt.
Reguläre Ausdrücke erlauben eine komplexe Überprüfung einer Zeichenkette auf Gültigkeit. Ein regulärer Ausdruck beginnt immer mit ^ und endet mit $.
Beispiel:
^[0-9]{5}$: String muss 5-stellig sein und darf nur Zahlen enthalten.
Kurzübersicht für reguläre Ausdrücke: https://msdn.microsoft.com/de-de/library/az24scfc(v=vs.110).aspx
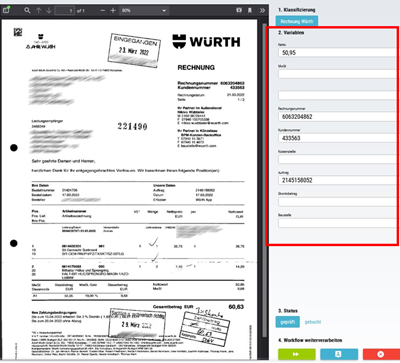 Der Inhalt einer Zone kann anhand eines regulären Ausdruckes gefiltert werden. Das bedeutet, dass nicht der komplette Inhalt einer Zone in die Zielvariable übernommen wird, sondern nur das Ergebnis des regulären Ausdruckes, der auf den Inhalt angewendet wird.
Der Inhalt einer Zone kann anhand eines regulären Ausdruckes gefiltert werden. Das bedeutet, dass nicht der komplette Inhalt einer Zone in die Zielvariable übernommen wird, sondern nur das Ergebnis des regulären Ausdruckes, der auf den Inhalt angewendet wird.
Mit regulären Ausdrücken lassen sich sehr komplexe Suchen und Filter realisieren. So können von einer Rechnung z.B. die Rechnungsnummer, Rechnungsbetrag oder die IBAN gelesen werden. Dazu müssen diese Werte nicht an derselben Stelle einer Rechnung stehen. Auf einer Rechnung steht der Rechnungsbetrag möglicherweise mittig. Auf einer anderen eher rechts. So lange aber die Position durch einen regulären Ausdruck auffindbar ist (z.B. weil immer Netto davorsteht) werden die gewünschten Werte gefunden und in der Zonenvariable gespeichert.
Beispiel: Zwischen dem Wort Netto oder Betrag und dem Wort EUR oder € werden alle Zahlzeichen gefunden und mit zwei Stellen nach einem Punkt oder Komma ausgegeben.
(?<=Netto|Betrag)(:)*([\s]*|(EUR|€))*(((\d*(,|.))*\d{2}))*
Da man sich nicht hundertprozentig sicher sein kann, dass alle auf diese Weise gesuchten Werte korrekt erkannt wurden, eignet sich das Feature Dokumentenprüfung sehr gut um im WebClient die Werte zu überprüfen und ggf. zu korrigieren oder zu ergänzen, siehe auch Dokumentenüberprüfung.
Entfernt beim erkannten Text der OCR-Zone Leerzeichen am Anfang und Ende des Textes (in der Zonen-Vorschau zu sehen).
Entfernt beim erkannten Text der OCR-Zone alle Leerzeichen innerhalb des Zoneninhalts - auch am Anfang und am Ende (in der Zonen-Vorschau zu sehen).
Wandelt den Text der OCR-Zone komplett in Kleinbuchstaben (in der Zonen-Vorschau zu sehen).
Bei der Erkennung von Barcodes kann es vorkommen, dass ein Barcode erkannt wird aber dessen Typ oder Inhalt nicht sofort gelesen werden kann. Meist liegt das daran, dass der Code leicht schräg auf der Vorlage abgebildet ist. IQ4docs kann dann versuchen den Bereich, in dem der Barcode gefunden wurde, schrittweise leicht zu drehen um die Erkennung des Codes zu ermöglichen.
Beachten Sie, dass diese Option rechenintensiv ist und die Erkennung verlangsamt. Aktivieren Sie die Option nur dann, wenn öfter Codes nicht erkannt werden.
Um ein besseres Ergebnis bei der Erkennung von Barcodes zu erhalten kann das Bild dazu invertiert werden.
Die Invertierung passiert intern und wird rein für die Verarbeitung verwendet. Der Scan selber wird anschließend immer normal (d.h. nicht invertiert) ausgegeben. Probieren Sie aus, welche Einstellung das beste Ergebnis für Ihre Scanvorlagen liefert.
- Auto: Das System entscheidet selber, ob die Verarbeitung mit einem normalen oder invertiertem Bild erfolgt.
- Normal: Die Verarbeitung erfolgt mit einem normalen Bild.
- Invers: Die Verarbeitung erfolgt mit einem invertierten Bild.
Sie können den Typ der Barcode-Erkennung auswählen. Smart bietet eine hohe Erkennungsgeschwindigkeit und Zuverlässigkeit. Treten bei sehr hohen Auflösungen der zu verarbeitenden Bilddatei Probleme auf (sehr lange Verarbeitungszeit oder falsche Erkennung von Codes), können Sie die Barcode-Erkennung auf Alternativ einstellen und prüfen, ob diese Methode bei Ihren Scanvorlagen bessere Ergebnisse liefert.
Geben Sie hier an, wie viele Worte vom Anfang des erkannten Textes verwendet werden sollen (z.B. 1 verwendet nur das erste Wort des erkannten Textes als Zonen Text (in der Zonen-Vorschau zu sehen).
Der ImageService bearbeitet Bilddaten (z.B. von Scans) und führt Dateiformatumwandlungen, Bildoptimierungen und OCR Erkennung durch. Er legt Dateien in gewünschten Zielverzeichnissen ab (je nach verwendetem Modul werden dazu die Rechte des Anwenders verwendet, der seinen Anwendungspool ausführt). Seine Logdatei ist Logs\ImageService.log.
